
Artificial intelligence has moved far beyond text and numbers. Today’s AI systems can see images, understand speech, read documents, and respond intelligently across multiple inputs at once. As per Precedence Research, the global multimodal AI market is projected to reach $3.43 billion in 2026 and $12.06 billion in 2030, growing at a CAGR of 36.92% between 2026 and 2030, driven by enterprise adoption across healthcare, retail, and digital platforms.
This transformation is being referred to as Multimodal AI or Multimodal Artificial Intelligence and is transforming the way human beings relate to machines. In this blog, we understand the working of a multimodal system, its models and tools, their practical uses, and trends that are influencing the future of multimodal systems.
What Is Multimodal AI, Really?
Fundamentally, a multimodal AI model operates and rationalizes across various data types, text, images, audio, video, and even sensor data in a united smart workflow.
In contrast to the traditional models, where the sole source of information is the natural language processing (NLP) algorithms, multimodal systems incorporate:
This convergence allows AI to comprehend context in the way that humans do, with the combination of what it sees, hears, and reads.
How Multimodal AI Works Behind the Scenes
The idea of multimodal systems involves constructing them by coordinating multiple AI models instead of using a single one. They each have their strengths as modalities, but their intelligence truly shines when they work in combination.
For example:
Frameworks such as LangChain and LlamaIndex are important in this case. They assist developers in connecting models, context management, and linking to external knowledge resources with high efficiency, particularly in advanced generative AI processes.
The Role of RAG, CAG, and Context-Aware Intelligence
Retrieval-augmented generation (RAG) is one of the most valuable enablers of multimodal intelligence. RAG enables the AI systems to retrieve pertinent external data, such as documents, images, and databases, and then create a response.
Now, more advanced architectures also include RAG and CAG (Context-Augmented Generation) to retain long-term memory and situational awareness. It is valuable with enterprise-level AI chatbots, medical diagnostics, legal research, and financial analysis, where precision and context are more important than innovation.
Read More: Multimodal RAG Explained: From Text to Images and Beyond
Where Multimodal AI Is Already Making an Impact
Multimodal AI is not a far-off future technology; it is already functioning in industries:
Multimodal AI Models in Practice (Quick Examples)
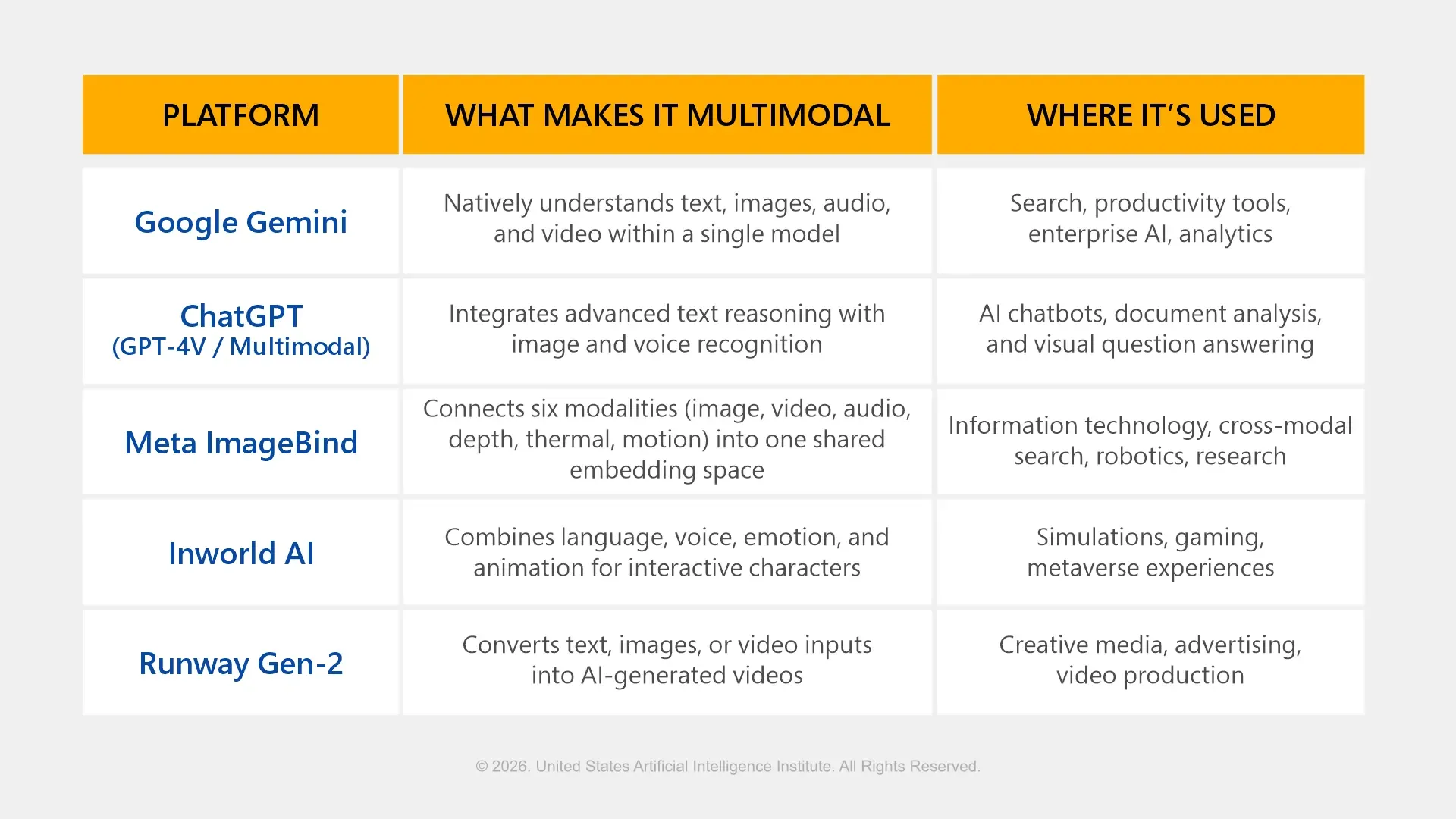
Multimodal AI and the Future of Generative Systems
The emergence of multimodal systems is among the generative AI trends of 2026. AI can no longer just give out text but can create:
The evolution significantly enhances user experience and decision-making, particularly in complex fields such as analytics, product design, and research.
Why Multimodal AI Skills Matter for AI Professionals
Multimodal knowledge is emerging as a form of career differentiator for professionals in AI and machine learning. Employers are getting more open to familiarity with:
This is why Top AI ML certifications such as CAIE™ – Certified Artificial Intelligence Engineer by USAII® offer hands-on learning focusing on real-world systems are gaining relevance. AI Certifications prepare professionals to build production-ready AI, not just experimental models.
From Experimentation to Real AI Applications
The power of multimodal AI lies in the fact that it can be taken beyond demos and deployed. By having the appropriate architecture, organizations will be able to create systems that learn and comprehend documents, images, and conversations in parallel, releasing insights that were once hidden in silos.
In the case of businesses, it implies intelligent automation. To the developers, it implies more expressive systems. And in the case of AI professionals, it is the skills that will allow them to withstand the competition in the future.
Conclusion: Beyond Text, Toward True Intelligence
Multimodal AI is a new stage in the history of machine perception and interaction with the world. Multimodal artificial intelligence makes AI more like a human being by integrating vision, voice, and language.
With increasingly complex AI applications and growing expectations, proficiency in multimodal systems, RAG systems, and generative workflows will characterize the future generation of AI leaders. The future of AI is not single-mode, but rather related, contextual, and highly multimodal.
FAQs
Which are the multimodal AI skills that AI teams need to focus on?
The teams require the data engineering strengths, the capacity to coordinate the model, the prompt design, and the assessment of various modalities.
What are the biggest data challenges in building multimodal AI systems?
Quality-labeled multimodal datasets are hard to find, costly, and difficult to align between formats such as video, audio, and text.
Is it possible to customize multimodal AI systems to domain-specific applications?
Yes, multimodal models can be fine-tuned to domain data and RAG pipelines to provide customization to other industries such as healthcare, finance, or manufacturing.


