
AI is evolving beyond just text, and multimodal retrieval-augmented generation (RAG) is at the forefront of this shift. But what exactly is multimodal RAG, and why is it becoming a key part of modern AI? Simply put, it allows AI models to seamlessly integrate and understand multiple types of data like text, images, audio, and more, so they can provide richer, context-aware outputs.
Unlike traditional RAG, multimodal systems create embeddings in a unified space: CNNs process images, transformers handle text, and specialized audio models manage sound. The rapid adoption of this technology is evident, with the global retrieval-augmented generation market projected to increase from USD 1.85 billion in 2025 to approximately USD 13.63 billion by 2030 (Precedence Research). In this blog, we’ll dive into multimodal RAG’s frameworks, real-world applications, and its transformative impact on the future of AI.
The Evolution of RAG
Retrieval Augmented Generation (RAG) started as a text-only model, enabling AI to retrieve documents and respond to questions based on documents. As time progressed, RAG evolved to include images, charts, and other data for multimodal RAG. Advanced AI models are designed for use with multiple data types.
Frameworks such as LangChain and LlamaIndex help AI engineers create retrieval pipelines and interact with application programming interfaces (APIs). Today, through advances in AI, agentic RAG autonomously retrieves and generates across modalities, creating a smarter and more autonomous AI experience.
How Multimodal RAG Works
In multimodal systems, the RAG architecture usually consists of three stages: generation, retrieval, and knowledge preparation.
1. Multimodal Knowledge Preparation
Encoded data for different modalities comes from an embedding as follows:
Contrastive learning is useful for aligning pairs of data from different modalities, such as an image and a caption, so that these items remain proximal in the system's memory. When a user subsequently asks the AI a text-based question, the AI can use the retrieved image or audio to respond.
2. Query Processing and Retrieval
When embeddings are saved in vector databases, queries are executed to find the nearest neighbors. Vector databases are optimized for low-latency searches and initiatives over large-scale datasets.
Traditional multimodal RAG pipelines use frameworks such as LangChain to execute queries, retrieve relevant data that can be summarized, and transform the relevant data to prepare it for the generative stage.
3. Context Building and Generation
Upon retrieval, the system fuses the related inputs. In early fusion, different inputs would have been merged into one representation, while in late fusion, each input type would remain its own representation until the very end of the process.
Afterwards, the multimodal LLM generated the response, which could be in the form of text, an image with text captioning, or an audio piece. This method also minimizes errors and maximizes the quality of the output.
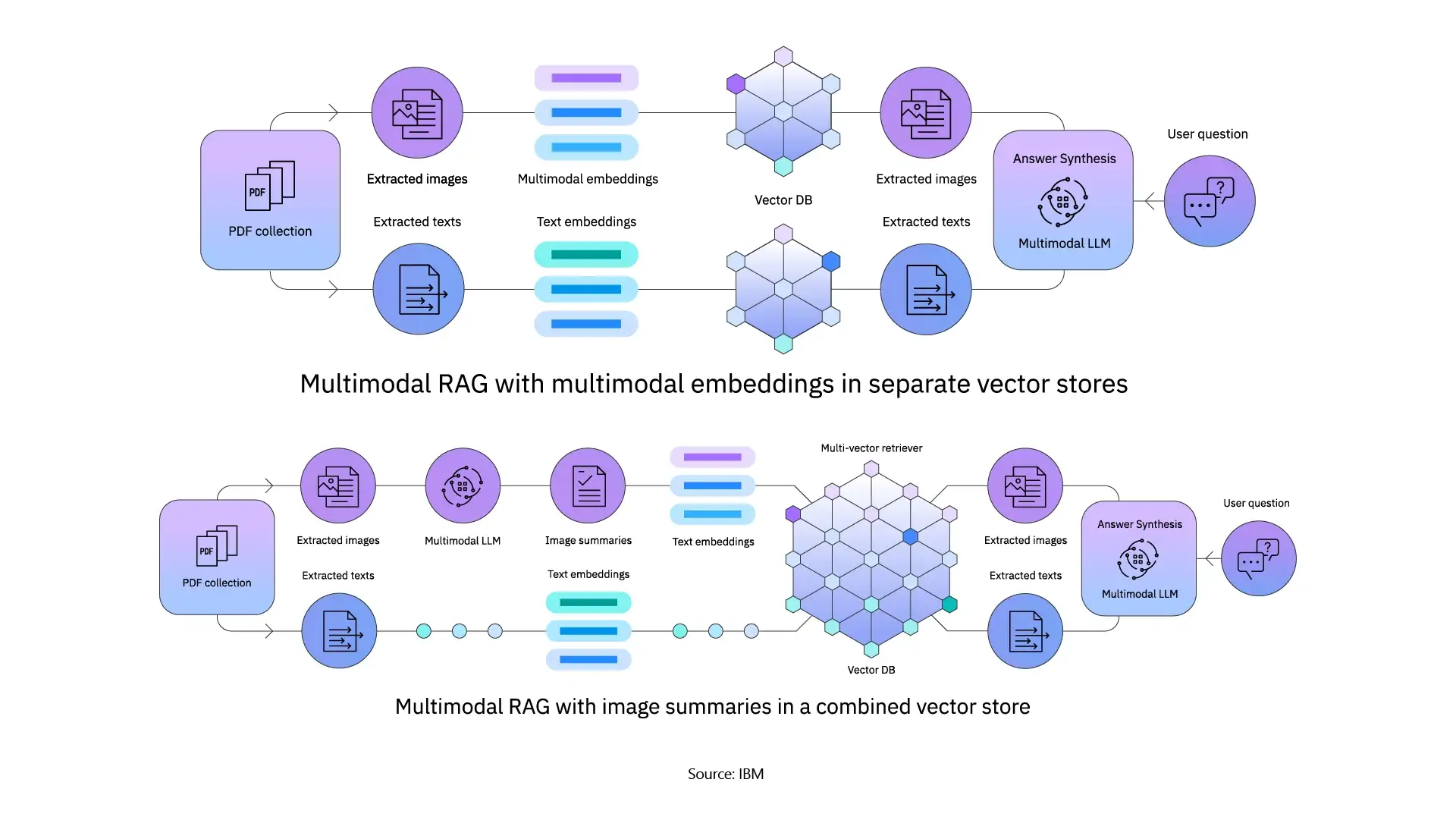
Approaches in Multimodal RAG
Applications of Multimodal RAG
The potential of multimodal RAG spans multiple domains:
In practical settings, multimodal RAG has outperformed single-modality systems with respect to accuracy and relevance, especially when combining information from text and images. This capability is seen in generative AI models like GPT-4V and LLaVA.
Integrating Multimodal RAG into AI Strategy
For businesses, multimodal RAG is more than a technical revolution; it’s a competitive edge. Organizations can bring their multimodal RAG systems into their workloads through APIs so that knowledge retrieval can be automated and they can make better decisions.
Critical strategies include:
To effectively leverage multimodal RAG as part of their enterprise AI strategy, leaders must create a concise and actionable AI roadmap. The USAII® CEO’s AI Blueprint Whitepaper 2026 offers a look at best practices for leaders to oversee AI adoption responsibly and effectively, ensuring that organizations reap the rewards of the transformative benefits of technologies such as multimodal RAG while managing the risk associated.
Challenges and Considerations
Even with the anticipated benefits, multimodal RAG is not without its obstacles:
The Future of Multimodal RAG
The growth of multimodal RAG suggests its increasing use across various fields, including healthcare, finance, education, and content creation.
Professionals pursuing machine learning certifications or careers as AI engineers can gain a competitive edge by completing programs like the Certified Artificial Intelligence Engineer (CAIE™) by USAII®, which equips learners with practical skills in AI, ML, and RAG workflows, preparing them to excel in next-generation AI systems
Conclusion
Multimodal RAG enhances generative AI by combining text, images, audio, and more to produce precise, context-aware outputs. It uses CNNs, vision-language transformers, and multimodal LLMs to seamlessly interact with complex multimodal prompts. From healthcare to enterprise knowledge and multimedia searches, it has altered people’s conceptions of AI.
As the field advances, AI engineers and generative prompt specialists will play a crucial role in shaping intelligent systems. For those looking to stay ahead of the curve, the AI Career Factsheet by USAII® offers key insights into where the AI job market is heading through 2026 and how to prepare for it.


