
AI is revolutionizing several sectors, including healthcare, finance, cybersecurity, and software development. AI systems, particularly large language models (LLMs), are used to automate communication, create code, and enable enterprise decision processes at scale. Fluency, however, does not always equal accuracy or reliability.
As per Precedence Research the global generative AI market will reach USD 255.67 billion by 2030, increasing from an estimated USD 55.51 billion market in 2026, as more enterprises adopt generative AI. This expansion causes an even greater need for technologies that enhance the accuracy of the response, reasoning, and expectation of the human subject.
A key technology that is driving this transformation is LLM reinforcement learning, which guides AI to learn the responses that humans prefer.
What Is Reinforcement Learning?
Reinforcement learning is a machine learning technique in which the AI system learns from feedback and rewards. The model is not only learning from static data; it is also learning about outcomes and changing its behaviour over time.
In the context of generative AI training, Reinforcement learning aids systems in
This is crucial because the ability to communicate relies heavily on context and judgement, something that prediction alone cannot fully capture.
Why Large Language Models Need Reinforcement Learning
First, most Large language models (LLMs) are initially trained on huge amounts of data, such as books, websites, research papers, and digital conversations. This provides models to respond to texts fluently, but not necessarily accurately or reliably.
Even a pre-trained model can still do the following
With the proliferation of AI usage in the business world, businesses required systems that could deliver more contextually relevant, accurate, and dependable results. This forced the development of extra refinement steps following the pre-training, beginning with supervised fine-tuning.
How Supervised Fine-Tuning Improves AI Responses
Supervised fine-tuning involves training AI models with a set of high-quality examples of both prompts and responses that have been carefully selected by human experts. These examples will benefit models for
This process not only enhances the efficiency and effectiveness of AI systems but also fosters a more user-friendly experience, particularly in business settings.
Supervised fine tuning, however, has its drawbacks due to the subjectivity of human preferences. There can be a number of correct answers, but it is preferable to humans to have clearer, safer, and more useful answers.
This challenge resulted in Reinforcement learning from human feedback.
What Is Reinforcement Learning from Human Feedback?
Reinforcement learning from human feedback (RLHF) is a learning method in which humans assess the responses from AI and provide feedback to influence the model's learning.
The AI system is not just memorizing examples but learning by comparing and optimizing.
Typically, it has three steps.
It is a model that provides several answers to a single prompt. Human reviewers rate those responses according to the following
The ranking is then used to train the reward model. A reward model predicts which human responses are preferred. It serves as a “scoring system” to assess the quality of the AI outputs during training.
This Is one of the most significant breakthroughs in LLM optimization methods since it enabled AI systems to learn from the human, rather than just the statistical.
The language model generates responses, which are then fed into the reward model to get scores. More responsive responses are rewarded; less responsive responses are penalized.
As training continues, the system learns increasingly to behave and react more effectively. This is the process that is the basis of modern LLM reinforcement learning systems.
How Reinforcement Learning Improves AI Alignment
An important goal for many companies creating AI today is achieving alignment of their models with the expectations, safety, and objectives of people and organizations.
AI alignment means that an AI model has been trained in a way that it behaves consistently with what a human expects, is safe, legal, and meets the needs of the organization creating the AI.
Reinforcement learning helps build alignment by providing the AI model with a means to identify what behaviors are acceptable and shouldn't be encouraged. This allows the AI to:
Different industries prioritize different optimization goals.
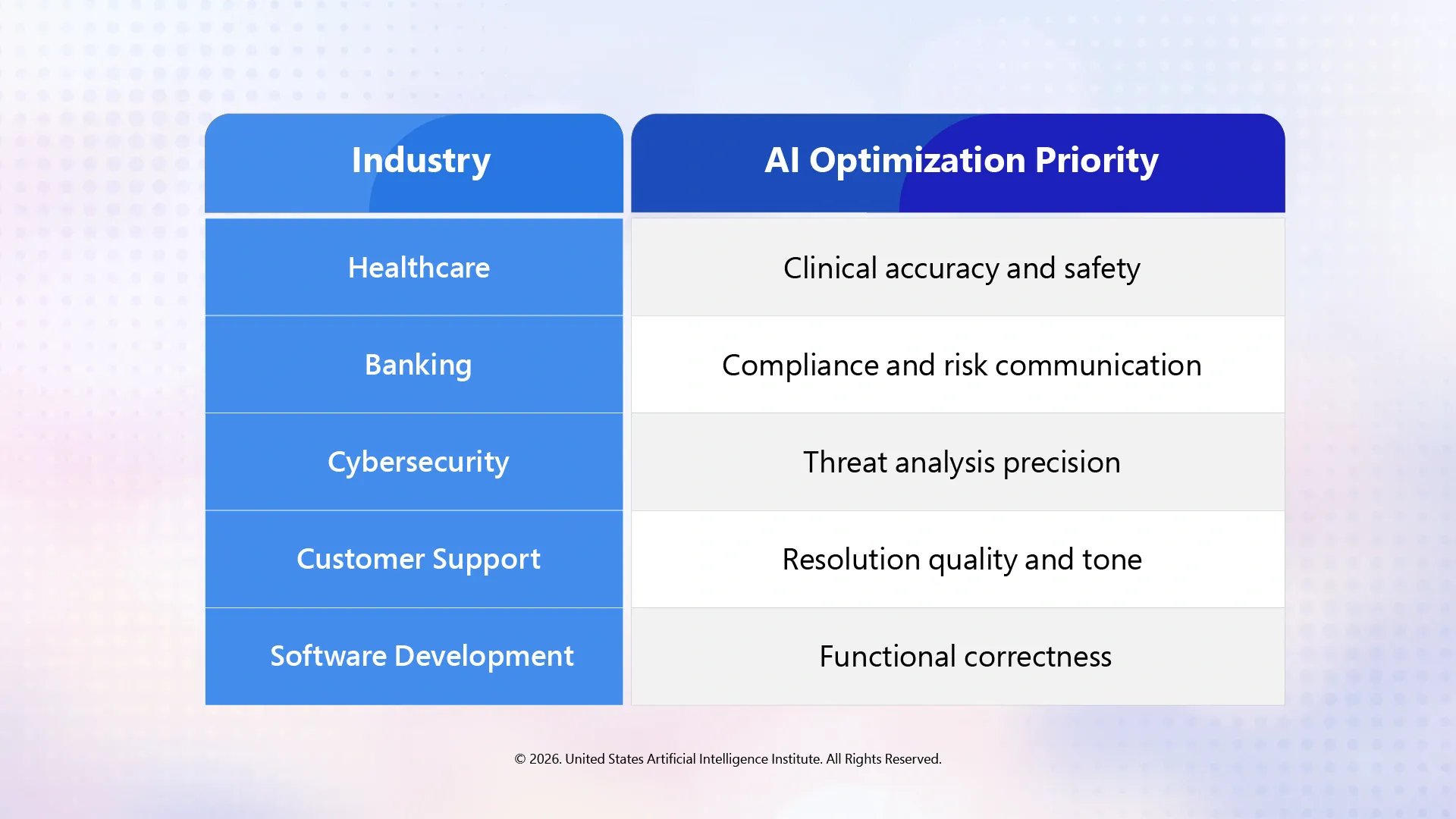
This ability to customize AI behavior is one reason reinforcement learning has become central to enterprise generative AI deployment.
Challenges in LLM Reinforcement Learning
Despite its advantages, LLM reinforcement learning still faces important operational challenges.
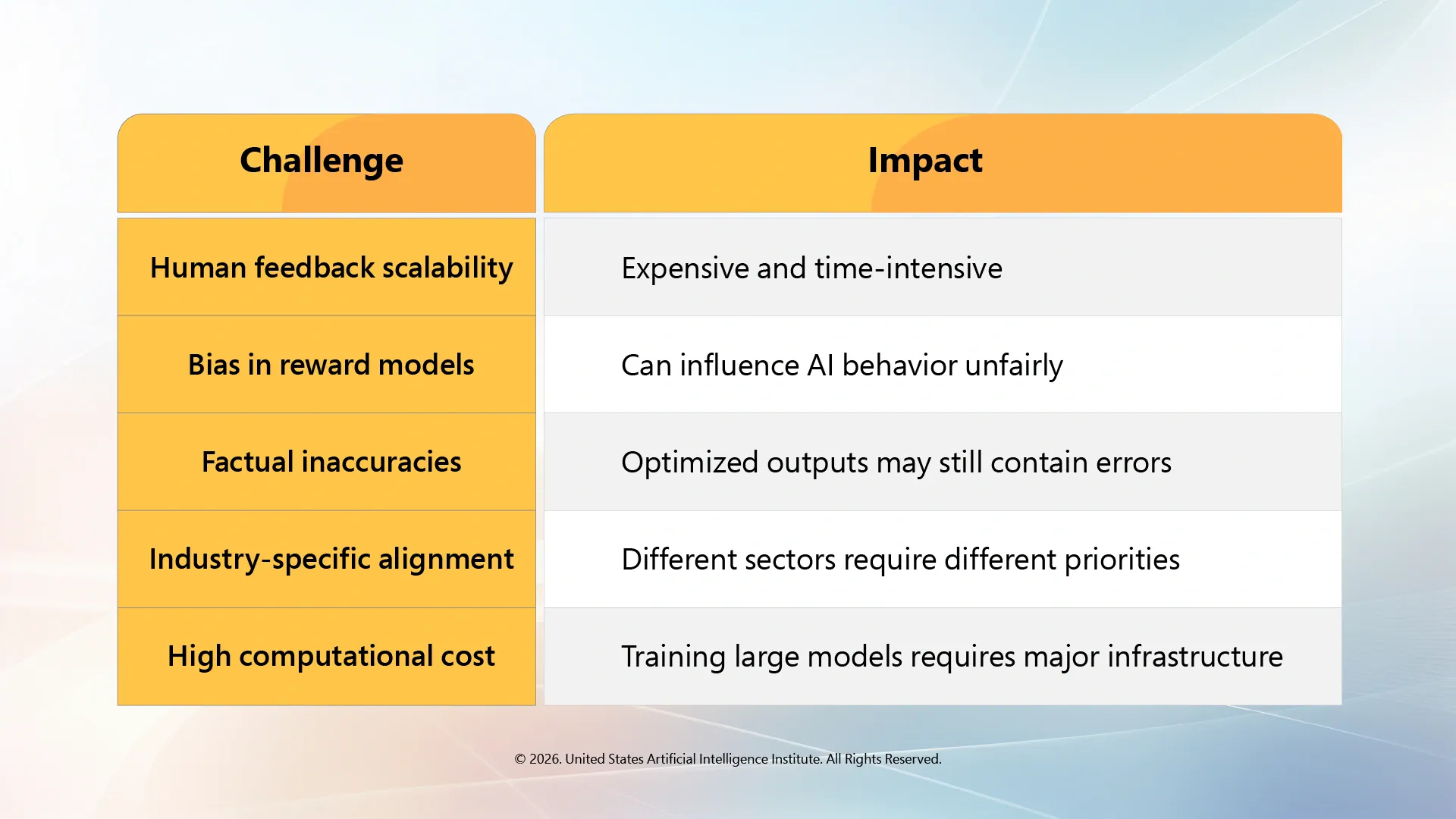
As AI systems become larger and more complex, balancing performance, safety, scalability, and cost remains a major challenge for AI developers.
Why AI Training Expertise Is Becoming More Valuable
With increasing use of generative AI by organizations, the need for professionals skilled in the training, optimization and deployment of AIs is on the rise.
As noted in USAII® Insights – The 2026 AI Skills Gap: Turning Training into Workforce Power, businesses are adopting AI faster than they can build AI-ready teams, increasing demand for practical AI Training Programs and Machine Learning Certifications focused on real-world implementation and LLM deployment.
Programs such as the Certified Artificial Intelligence Engineer (CAIE™) by USAII® help professionals develop applied expertise in AI engineering, machine learning workflows, neural networks, and enterprise AI implementation.
As hiring requirements continue evolving, Top AI ML Certifications are becoming increasingly valuable for professionals entering AI-focused roles.
Final Thoughts
Fluency alone does not define modern AI. Now it is about how closely the AI will sync with both people’s expectations and the demands of business. Long-term memory and reinforcement learning of large language models creates this alignment, and to utilize AI successfully, individuals must understand how both work to navigate through the significant amounts of AI implementation that currently exist on the market.
FAQs
Can reinforcement learning improve AI personalization?
Yes, reinforcement learning helps AI systems adapt responses based on user preferences and interaction patterns.
Is reinforcement learning used only for text-based AI models?
No, reinforcement learning is also widely used in robotics, autonomous systems, gaming AI, and recommendation engines.
What skills are important for working with LLM reinforcement learning?
Professionals need knowledge of machine learning, prompt optimization, model evaluation, AI governance, and generative AI workflows.


